Running jobs
Table of contents
A basic single-node job
In order to run an instance of a container, running the command defined in the image’s entrypoint, all you need to do is to specify the Docker Hub image name:
prominence create eoscprominence/testpi
output
Job created with id 3101
When a job has been successfully submitted an (integer) ID will be returned. Alternatively, a command (and arguments) can be specified. For example:
prominence create centos:7 "/bin/sleep 100"
The command of course should exist within the container. If arguments need to be specified you should put the command and any arguments inside a single set of double quotes, as in the example above.
To run multiple commands inside the same container, use /bin/bash -c with the commands enclosed in quotes and seperated by semicolons, for example:
prominence create centos:7 "/bin/bash -c \"date; sleep 10; date\""
This is of course assuming /bin/bash exists inside the container image.
MPI jobs
To run an MPI job, you need to specify either --openmpi for Open MPI, --intelmpi for Intel MPI and --mpich for MPICH. For multi-node jobs the number of nodes required should also be specified. For example:
prominence create --openmpi --nodes 4 alahiff/openmpi-hello-world:latest /mpi_hello_world
The number of processes to run per node is assumed to be the same as the number of cores available per node. If the number of cores available per node is more than the requested number of cores all cores will be used. This behaviour can be changed by using --procs-per-node to define the number of processes per node to use. This can be useful if you want to ensure that the number of processes per node is fixed and won’t depend on the size of the machines.
Unlike single-node jobs, a command to run (and optionally any arguments) must be specified. If an entrypoint is defined in the container image it will be ignored.
Note: If the total number of CPUs required is small, e.g. 16 cores or less, for best performance use a single node rather than multiple nodes unnecessarily. This is especially important on resources which do not have low-latency network interconnects.
MPI on hosts is not used at all for running MPI jobs as this could result in incompatibilities. Only MPI executables and libraries inside the supplied container image are used. For example, for Open MPI:
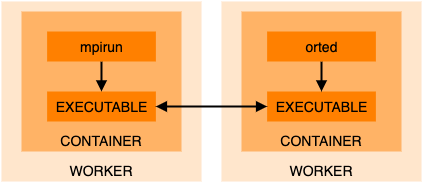
Hybrid MPI-OpenMP jobs
In this situation the number of MPI processes to run per node must be specified using --procs-per-node and the environment variable OMP_NUM_THREADS should be set to the required number of OpenMP threads per MPI process.
In the following example we have 2 nodes with 4 CPUs each, and we run 2 MPI processes on each node, where each MPI process runs 2 OpenMP threads:
prominence create --cpus 4 \
--memory 4 \
--nodes 2 \
--procs-per-node 2 \
--openmpi \
--env OMP_NUM_THREADS=2 \
--artifact https://github.com/lammps/lammps/archive/stable_12Dec2018.tar.gz \
--workdir lammps-stable_12Dec2018/bench \
alahiff/lammps-openmpi-omp "lmp_mpi -sf omp -in in.lj"
Resources
Fixed resources
By default a job will be run with 1 CPU and 1 GB memory but this can easily be changed. The following resources can be specified:
- CPU cores
- Memory (total memory for the job in GB)
- Disk (in GB)
- Maximum runtime (in mins)
CPU cores and memory can be specified using the --cpus and --memory options. A disk size can also be specified using --disk. For MPI jobs cpus and memory refer to the number of CPU cores per node and memory per node, not the totals summed across all nodes.
Here is an example running an MPI job on 4 nodes where each node has 2 CPUs and 8 GB memory, there is a shared 20 GB disk accessible by all 4 nodes, and the maximum runtime is 1000 minutes:
prominence create --openmpi \
--nodes 4 \
--cpus 2 \
--memory 8 \
--disk 20 \
--runtime 1000 \
alahiff/geant4mpi:1.3a3
By default a 10 GB disk is available to jobs. The default maximum runtime is 720 minutes.
Dynamic resources
This functionality is sometimes referred to as moldable jobs.
In some situations it can be useful to specify a range of CPU cores rather than specifying a single number. For example, you may prefer to have 32 cores but if 32 cores are not currently available you would be happy to have anywhere between 16 and 32 cores. In this case instead of specifying --cpus use --cpus-range, for example --cpus-range 16,32.
Alternatively --cpus-options can be used to specify two possible numbers of CPU cores. For example, with --cpus-options 16,32 the job will use 32 cores if available, but otherwise 16 cores will be used. Both of these options can help to ensure jobs will start running as quickly as possible but with reduced performance due to the reduction in numbers of CPUs available.
When either of --cpus-range or --cpus-options are used it can be beneficial to specify memory in terms of memory per core rather than total memory of the node. In this case use --memory-per-cpu rather than --memory.
For multi-node MPI jobs, instead of specifying a fixed number of nodes, a range of total number of CPU cores can be specified instead using --total-cpus-range. For example:
prominence create --openmpi \
--total-cpus-range 16,32 \
--cpus-range 4,8 \
--memory-per-cpu 2 \
alahiff/geant4mpi:1.3a3
In this case, if possible, the job will run with the maximum number of CPUs specified (32) and the maximum number of CPUs per node (8), ensuring that the number of nodes is minimised. If these resources are not available then the number of nodes may be increased to meet the maximum number of total CPUs and/or the total number of CPUs may be reduced.
Working directory
By default the current working directory is scratch space made available inside the container. The path to this directory is also specified by the environment variables HOME, TEMP and TMP.
To specify a different working directory use --workdir.
Note: Remember that you should not try to write inside the container’s filesystem as this may be prevented by the container runtime or result in permission problems.
Multiple tasks in a single job
By default a job will run a single command inside a single container. However, it is possible to instead run multiple sequential tasks within a single job. Each task will have access to the same temporary storage, so transient files generated by one task are accessible by other tasks. If more than one task uses the same container image, the container image will only be pulled once and the cached image used for any further tasks using the same image.
To run multiple tasks in a single job requires the user to define a JSON job description which can then be submitted using the CLI. A simple way to do this is to start by using prominence create --dry-run (see here) to create the JSON description for a job with a single task, and then modify this as necessary.
Below a simple example is shown which runs a CentOS container followed by a Ubuntu container:
{
"name": "multiple-tasks",
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "centos:7",
"cmd": "cat /etc/redhat-release",
"runtime": "singularity"
},
{
"image": "ubuntu:16.04",
"cmd": "cat /etc/debian_version",
"runtime": "singularity"
}
]
}
Assuming the above is stored in a file called single-job-multiple-tasks.json, it can be submitted by running:
prominence run single-job-multiple-tasks.json
Note: Different tasks do not have to use the same container runtime. It is possible for some tasks to use udocker while others use Singularity.
Automatic retries for job and task failures
If multiple tasks are defined and a task fails (i.e. the exit code is not 0), no more tasks will be executed unless ignoreTaskFailures in policies is specified (see here).
It is possible for failing tasks to be retried but by default this will not happen. The maximum number of retries can be specified using the --task-retries option to prominence create.
It is also possible for failing jobs to be retried. The maximum number of retries can be specified using the --retries option.
Cloning jobs
If a job fails it’s also possible to re-run the original job using prominence clone. This creates a copy of an existing job, for example, to clone a job with id 51239:
prominence clone job 51239
The cloned job is assinged a new id. Jobs can be cloned in any state, including idle and running jobs.