Directed acyclic graphs
Overview
In order to submit a workflow the first step is to write a JSON description of the workflow. This is just a list of the definitions of the individual jobs (which can be created easily using prominence create --dry-run, see here) along with the dependencies between them. Each dependency defines a parent and its children. The basic structure is:
{
"name": "test-workflow-1",
"jobs": [
{...},
{...}
],
"dependencies": {
"parent_job": ["child_job_1", ...],
...
}
}
Each of the individual jobs must have defined names as these are used in order to define the dependencies. Unlike some workflow languages like CWL or WDL, in PROMINENCE abstract dependencies are used rather than dependencies derived from data flow. This means that dependencies need to be defined in terms of job names rather than being based on job inputs and outputs. Parent jobs are run before children.
It is important to note that the resources requirements for the individual jobs can be (and must be!) specified. This will mean that each step in a workflow will only use the resources it requires. Jobs within a single workflow can of course request very different resources, which makes it possible for workflows to have both HTC and HPC steps.
By default the number of retries is zero, which means that if a job fails the workflow will fail. Any jobs which depend on a failed job will not be attempted. If the number of retries is set to one or more, if an individual job fails (i.e. exit code is not 0) it will be retried up to the specified number of times. To set a maximum number of retries, include maximumRetries in the workflow definition, e.g.
"policies": {
"maximumRetries": 2
}
Examples
It is worthwhile to look at some simple examples in order to understand how to define workflows.
Multiple steps
Here we consider a simple workflow consisting of multiple sequential steps, e.g.

In this example job_A will run first, followed by job_B, finally followed by job_C. A basic JSON description is shown below:
{
"name": "multi-step-workflow",
"jobs": [
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_B"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_C"
}
],
"dependencies": {
"job_A": ["job_B"],
"job_B": ["job_C"]
}
}
See here for a visualisation of the above JSON.
Scatter-gather
He we consider the common type of workflow where a number of jobs can run in parallel. Once these jobs have completed another job will run. Typically this final step will take output generated from all the previous jobs. For example:
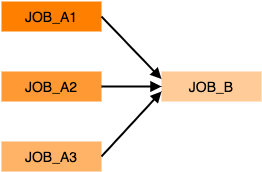
A basic JSON description is shown below:
{
"name": "scatter-gather-workflow",
"jobs": [
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A1"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A2"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_A3"
},
{
"resources": {
"nodes": 1,
"cpus": 1,
"memory": 1,
"disk": 10
},
"tasks": [
{
"image": "busybox",
"runtime": "singularity",
"cmd": "date"
}
],
"name": "job_B"
}
],
"dependencies": {
"job_A1": ["job_B"],
"job_A2": ["job_B"],
"job_A3": ["job_B"]
}
}
See here for a visualisation of the above JSON.